大致了解了HMM后,我们迈进进kaldi的源码大门,目的在于大致理解kaldi如何实现,还有MFCC如何提取特征的。
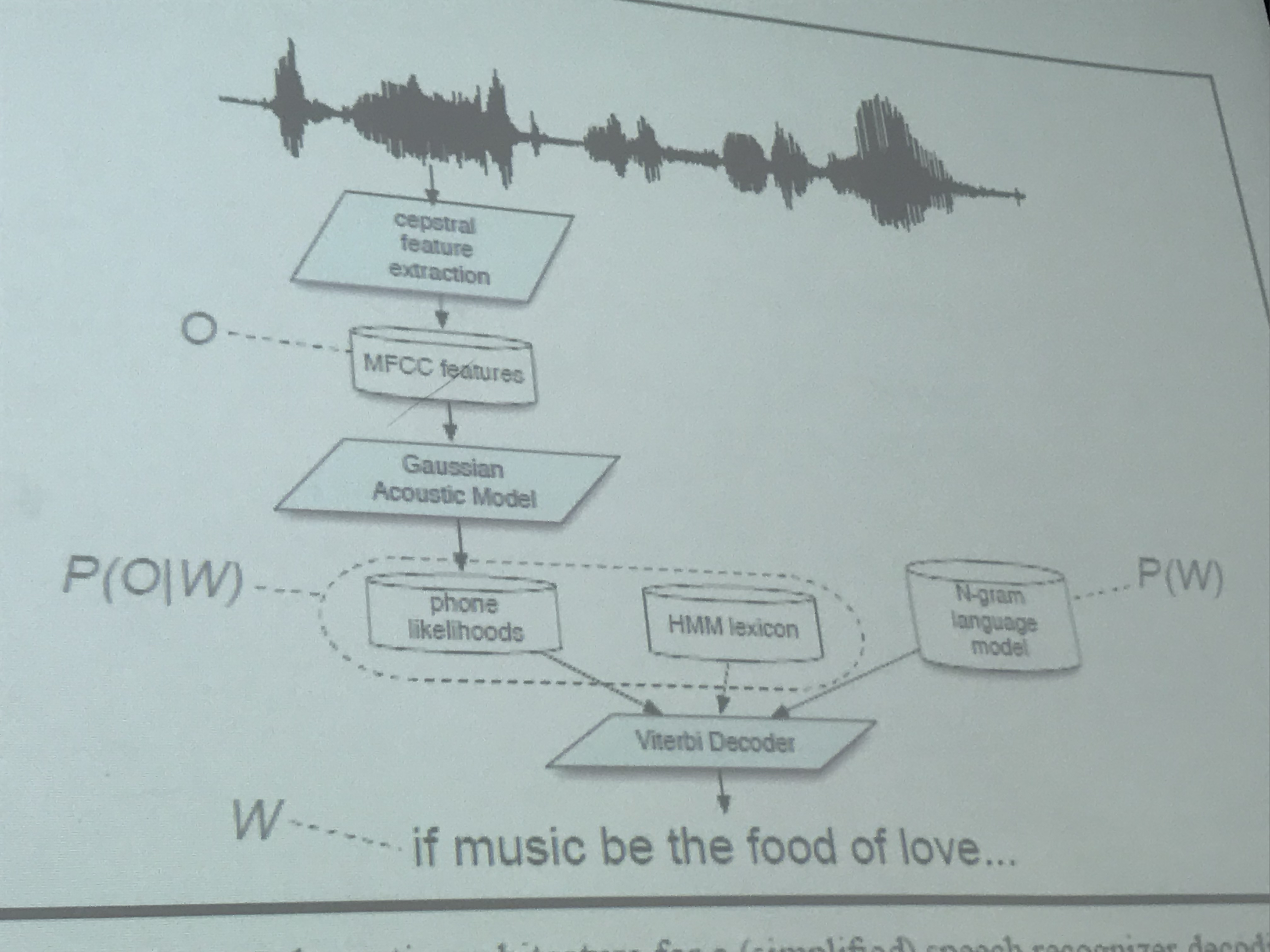
我们选取了清华 thchs30 作为数据集,之前懵懵懂懂的跑过一些kaldi自带的简单样例,因为我是使用VMware(后悔买电脑时没有买大一点磁盘,这样划系统了用起来更爽),清华数据集足足有快7G,学长装了两CPU才跑出来,我索性先不跑了…直接先从跑好的文件里学习。
附上数据集下载连接:
初步印象
文件多为 .sh 和 .pl 后缀,前者为shell所编写的脚本文件,后者为Perl所写,最开始让老师让回去看run.sh,课上一晃而过我庆幸自己刚刚学完Linux以及shell心想应该还可以大致看看,然而当打开文件后我真是高估了我自己。 不得不说上课所学的掌握和实际应用的理解完全两码事。
run.sh 的前五条语句
run.sh 的前五条语句其实就是一些初始化和配置环境变量的过程:
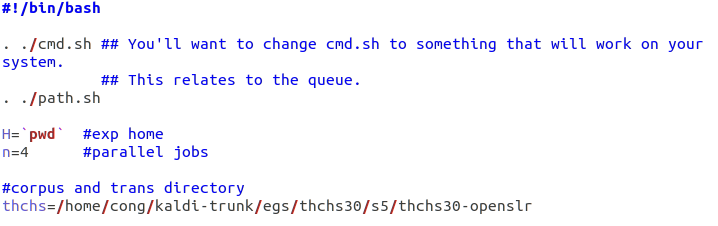
- . ./cmd.sh
这里需要注意的是前面的两个点之间是有一个空格的并不是直接表示上层目录,第一个 . 表示当前目录下的操作,空格后第二个 . 仍表示当前目录下,该语句就是执行当前目录下的cmd.sh文件。
cmd.sh内容如下:
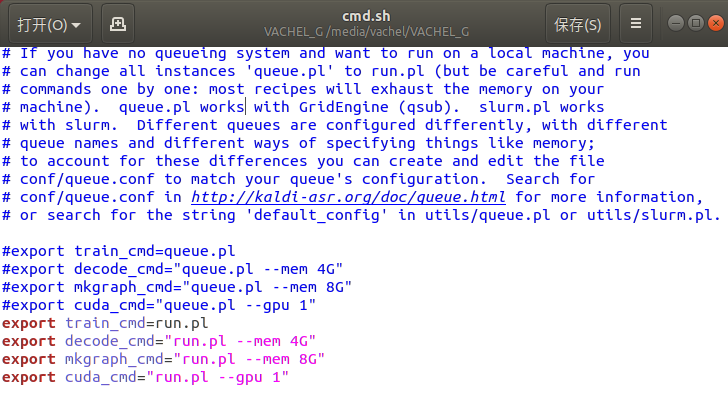
里面要把cmd后缀变量的赋值换成本地的文件。
- . ./path.sh
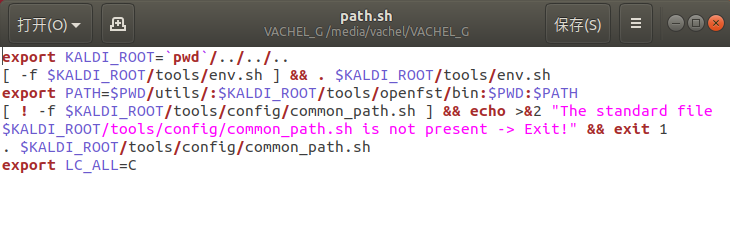
path.sh是完成环境变量的一些设置,将KALDI_ROOT赋值为当前目录下上移三层目录,再判断指定位置的env.sh这个环境配置文件是否为普通文件,并且执行。PATH与LC_ALL也是如此,其中涉及到:符,分割了多个路径,把这些路径都加入了指定变量里。还有 >&2 表示标准错误输出。
- H = ‘pwd’;n = 4;
H赋值为当前路径,n代表并行数量。
- thchs=… #corpus and trans directory
存放了数据集的内容。
data preparation

数据准备阶段执行 thchs-30_data_prep.sh 文件,同时传入本地路径,以及数据集路径下/data_thchs30
thchs-30_data_prep.sh:
#!/bin/bash
# Copyright 2016 Tsinghua University (Author: Dong Wang, Xuewei Zhang). Apache 2.0.
# 2016 LeSpeech (Author: Xingyu Na)
#This script pepares the data directory for thchs30 recipe.
#It reads the corpus and get wav.scp and transcriptions.
dir=$1
corpus_dir=$2
cd $dir
echo "creating data/{train,dev,test}"
mkdir -p data/{train,dev,test}
#create wav.scp, utt2spk.scp, spk2utt.scp, text
(
for x in train dev test; do
echo "cleaning data/$x"
cd $dir/data/$x
rm -rf wav.scp utt2spk spk2utt word.txt phone.txt text
echo "preparing scps and text in data/$x"
#updated new "for loop" figured out the compatibility issue with Mac created by Xi Chen, in 03/06/2018
#for nn in `find $corpus_dir/$x/*.wav | sort -u | xargs -i basename {} .wav`; do
for nn in `find $corpus_dir/$x -name "*.wav" | sort -u | xargs -I {} basename {} .wav`; do
spkid=`echo $nn | awk -F"_" '{print "" $1}'`
spk_char=`echo $spkid | sed 's/\([A-Z]\).*/\1/'`
spk_num=`echo $spkid | sed 's/[A-Z]\([0-9]\)/\1/'`
spkid=$(printf '%s%.2d' "$spk_char" "$spk_num")
utt_num=`echo $nn | awk -F"_" '{print $2}'`
uttid=$(printf '%s%.2d_%.3d' "$spk_char" "$spk_num" "$utt_num")
echo $uttid $corpus_dir/$x/$nn.wav >> wav.scp
echo $uttid $spkid >> utt2spk
echo $uttid `sed -n 1p $corpus_dir/data/$nn.wav.trn` >> word.txt
echo $uttid `sed -n 3p $corpus_dir/data/$nn.wav.trn` >> phone.txt
done
cp word.txt text
sort wav.scp -o wav.scp
sort utt2spk -o utt2spk
sort text -o text
sort phone.txt -o phone.txt
done
) || exit 1
utils/utt2spk_to_spk2utt.pl data/train/utt2spk > data/train/spk2utt
utils/utt2spk_to_spk2utt.pl data/dev/utt2spk > data/dev/spk2utt
utils/utt2spk_to_spk2utt.pl data/test/utt2spk > data/test/spk2utt
echo "creating test_phone for phone decoding"
(
rm -rf data/test_phone && cp -R data/test data/test_phone || exit 1
cd data/test_phone && rm text && cp phone.txt text || exit 1
)
}
data preparation 对应分析
#!/bin/bash
#shell语言标准开头
# Copyright 2016 Tsinghua University (Author: Dong Wang, Xuewei Zhang). Apache 2.0.
# 2016 LeSpeech (Author: Xingyu Na)
#This script pepares the data directory for thchs30 recipe.
#It reads the corpus and get wav.scp and transcriptions.
dir=$1
corpus_dir=$2
#将刚刚run.sh中的两个参数分辨传递给dir,corpus_dir,分别是当前路径和数据集地址。
cd $dir
echo "creating data/{train,dev,test}"
mkdir -p data/{train,dev,test}
#打开到当前目录,输出并创建三个指定名字文件夹。
#create wav.scp, utt2spk.scp, spk2utt.scp, text
(
for x in train dev test; do
echo "cleaning data/$x"
cd $dir/data/$x
rm -rf wav.scp utt2spk spk2utt word.txt phone.txt text
echo "preparing scps and text in data/$x"
#首先完成数据清洗,进入train dev test这三个文件夹,强制递归删除掉wav.scp utt2spk spk2utt word.txt phone.txt text这些文件。
#updated new "for loop" figured out the compatibility issue with Mac created by Xi Chen, in 03/06/2018
#for nn in `find $corpus_dir/$x/*.wav | sort -u | xargs -i basename {} .wav`; do
for nn in `find $corpus_dir/$x -name "*.wav" | sort -u | xargs -I {} basename {} .wav`; do
# 这里是查找数据集目录下以 .wav 结尾的文件,并去重排序,并取出基础名(去除路径)。
# 这里多解释一下xargs的作用,xargs是将前面的标准输出作为后面指定命令的参数,也通常与管道符连用,
# 因为管道符是将前面的标准输出座位后面的标准输入,而无法作为后面指定命令的参数,而I选项代表用{}
# 来表示管道前标准输出的内容。
# 坊间有一种说法,将 xargs 解读为乘号(x)和参数(args)的合体,很形象地表达了 xargs 的作用所在。
spkid=`echo $nn | awk -F"_" '{print "" $1}'`
spk_char=`echo $spkid | sed 's/\([A-Z]\).*/\1/'`
spk_num=`echo $spkid | sed 's/[A-Z]\([0-9]\)/\1/'`
spkid=$(printf '%s%.2d' "$spk_char" "$spk_num")
utt_num=`echo $nn | awk -F"_" '{print $2}'`
uttid=$(printf '%s%.2d_%.3d' "$spk_char" "$spk_num" "$utt_num")
echo $uttid $corpus_dir/$x/$nn.wav >> wav.scp
echo $uttid $spkid >> utt2spk
echo $uttid `sed -n 1p $corpus_dir/data/$nn.wav.trn` >> word.txt
echo $uttid `sed -n 3p $corpus_dir/data/$nn.wav.trn` >> phone.txt
done
# 这里就是对就每一个.mav文件进行进行操作
# 这里我们得先去看一下数据 .mav ,例如文件的命名都是 A01_001.mav 这种形式。
# spkid(speak ID)= 文件名以"_"隔开,并取第一块使用 (例如值为A01)
# ps:awk是一种强大的文本分析工具 -F选项可以指定输入文件折分隔符。
# spk_char = 把spkid中的字母取出来 (例如值为A)
# ps:sed可依照脚本的指令来处理、编辑文本文件,通常与正则表达式连用,正则表达式 s/A/B表示替换。
# 这里的A就是指 \([A-Z]\).* 第一个字符是大写字母,第二个字符是.可以表示任何除\n外的字符,第三个字符是.的重复
# 而这里字母之所以用()括起来,是因为B中用\1来捕获组 ,就是第一个小括号内的值,也就完成了替换
# spk_num = 把spkid中的数字取出来 (例如值为01)
# ps:这与上一个大同小异,主要分析一下正则表达式,同样是s/A/B的替换结构
# A表示[A-Z]\([0-9]\),这里有一个小小的疑惑,为什么[0-9]这样的结构只能取出一个字符却把01都取出来了
# 在这里 我经过实验发现,替换结构中的A若是没有完整的表达出字符从左到右的情况,则未被表达的字符会按原样输出
# 而同样()把字母后的所有数字字符都表示了,再使用\1进行捕获替换就确定了num的值
# spkid=$(printf '%s%.2d' "$spk_char" "$spk_num")
# 学过C语言应该对printf不陌生,就是格式化了一下spkid,其中spk_num取两位有效位
# utt_num = 语音号
# 语音号采用文件名以"_"隔开的第二部分。
# uttid = 语音信息
# 对所有信息进行一个标准化。
cp word.txt text
sort wav.scp -o wav.scp
sort utt2spk -o utt2spk
sort text -o text
sort phone.txt -o phone.txt
#从word.txt拷贝出text,排序四个文件。
done
) || exit 1
utils/utt2spk_to_spk2utt.pl data/train/utt2spk > data/train/spk2utt
utils/utt2spk_to_spk2utt.pl data/dev/utt2spk > data/dev/spk2utt
utils/utt2spk_to_spk2utt.pl data/test/utt2spk > data/test/spk2utt
#在train、dev、test中都对应有spk2utt
echo "creating test_phone for phone decoding"
(
rm -rf data/test_phone && cp -R data/test data/test_phone || exit 1
cd data/test_phone && rm text && cp phone.txt text || exit 1
)
}
总结分析
该部分的数据准备与数据相关,保存在data/train、data/dev、data/test之类的目录下,“数据”部分与特定的录音数据有关,包括训练测试集划分、音频分段、文本标注、发音标注、说话人信息等。