run.sh的第二块内容就是创建提取mfcc特征,对应着又是几个脚本文件,包括make_mfcc.sh,ompute_cmvn_stats.sh等,分析过后发现还是为了确保数据准确性所做的检查数据集的文件操作,并不是就约等于所做的理论分析内容。
#produce MFCC features
rm -rf data/mfcc && mkdir -p data/mfcc && cp -R data/{train,dev,test,test_phone} data/mfcc || exit 1;
#这里同样和数据准备类似,要先删除原有的mfcc特征,并且递归拷贝数据准备创建的几个文件到mfcc下。
for x in train dev test; do
#make mfcc
steps/make_mfcc.sh --nj $n --cmd "$train_cmd" data/mfcc/$x exp/make_mfcc/$x mfcc/$x || exit 1;
# 分别对训练集、验证集、测试集创建MFCC模型,以下将对make_mfcc.sh进行分析。
#compute cmvn
steps/compute_cmvn_stats.sh data/mfcc/$x exp/mfcc_cmvn/$x mfcc/$x || exit 1;
# 理论中设计的倒谱一概念,在这里需要对mfcc三个集合中的倒谱均值和方差归一化 。
done
一、make_mfcc.sh
我原本以为这个文件会与上次所分析的理论对应 但其实分析脚本下来还是一些和文件处理相关的
这里说明一下shell的参数具体是这样的:
$# 表示提供到shell脚本或者函数的参数总数;
$1 表示第一个参数。
-ne 表示 不等于
另外:整数比较-eq 等于,如:if [“$a” -eq “$b” ]
-ne 不等于,如:if [“$a” -ne “$b” ]
-gt 大于,如:if [“$a” -gt “$b” ]
-ge大于等于,如:if [“$a” -ge “$b” ]
-lt 小于,如:if [“$a” -lt “$b” ]
-le 小于等于,如:if [“$a” -le “$b” ]
< 小于(需要双括号),如:((“$a” < “$b”))
<= 小于等于(需要双括号),如:((“$a” <= “$b”))
‘>‘ 大于(需要双括号),如:((“$a” “$b”))
‘>=’ 大于等于(需要双括号),如:((“$a” >= “$b”))
另外:$?是shell变量,表示”最后一次执行命令”的退出状态.0为成功,非0为失败.
文件如下:
#!/bin/bash
# Copyright 2012-2016 Johns Hopkins University (Author: Daniel Povey)
# Apache 2.0
# To be run from .. (one directory up from here)
# see ../run.sh for example
# Begin configuration section.
nj=4
# 共同工作进程数
cmd=run.pl
# 调用run.pl
mfcc_config=conf/mfcc.conf
#十二个系数以外的能量要不要
#已注释抽样率 8000 足够
compress=true
# 启用了压缩
write_utt2num_frames=false # if true writes utt2num_frames
# End configuration section.
# 打印这个脚本的名称以及所有的参数
echo "$0 $@" # Print the command line for logging
# 这里是打印命令行到日志,$0为执行的命令 $@表示所有参数脚本的内容
# 加载path.sh和parse_options.sh
if [ -f path.sh ]; then . ./path.sh; fi #设置环境变量
# 如果存在path.sh那么就执行它
. parse_options.sh || exit 1;
# parse_options.sh解析命令行选项
# 如果参数少于1或者大于3就提示使用脚本错误
if [ $# -lt 1 ] || [ $# -gt 3 ]; then
#如果参数小于一个或大于三个 标准错误输出 注释
echo "Usage: $0 [options] <data-dir> [<log-dir> [<mfcc-dir>] ]"; #第二个是日志
echo "e.g.: $0 data/train exp/make_mfcc/train mfcc"
echo "Note: <log-dir> defaults to <data-dir>/log, and <mfccdir> defaults to <data-dir>/data"
echo "Options: "
echo " --mfcc-config <config-file> # config passed to compute-mfcc-feats "
echo " --nj <nj> # number of parallel jobs"
echo " --cmd (utils/run.pl|utils/queue.pl <queue opts>) # how to run jobs."
echo " --write-utt2num-frames <true|false> # If true, write utt2num_frames file."
exit 1;
fi
# 这块就是如果不符合这些参数列表,则需要更改符合这些参数。
data=$1 # 将第一个参数赋给data,其实就是上面这个说明中说的<data-dir>
# 判断如果参数总数大于等于2,则将第二个参数赋给logdir,否则将data下的log路径赋给logdir
if [ $# -ge 2 ]; then # 如果参数大于等于2
logdir=$2 # logdir=exp/make_mfcc/train
else
logdir=$data/log
fi
if [ $# -ge 3 ]; then # 判断如果参数总数大于等于3,则将第三个参数赋给mfccdir,否则将data下的data路径赋给mfccdir
mfccdir=$3 #mfccdir=mfcc/train
else
mfccdir=$data/data
fi
# make $mfccdir an absolute pathname.
mfccdir=`perl -e '($dir,$pwd)= @ARGV; if($dir!~m:^/:) { $dir = "$pwd/$dir"; } print $dir; ' $mfccdir ${PWD}`
# -e 执行后面的语句
# !否定 ~匹配 ^开头 /代表根目录
# 若不是绝对路径改成
# 这块是调用perl脚本来创建目录,给mfccdir赋值一个绝对路径名称
# @ARGV首先是一个数组,不管脚本里有没有把它写出来,它始终是存在的。@ARGV是Perl默认用来接收参数的数组,这些参数来源于用户在命令行上输入的参数。
#utterence
# use "name" as part of name of the archive.
# 使用“名称”作为文件名称的一部分
name=`basename $data`
# 创建mfcc特征文件夹和log文件夹
mkdir -p $mfccdir || exit 1;
mkdir -p $logdir || exit 1;
# 创建两个目录
# 如果之前有执行过生成了特征信息文件则备份
if [ -f $data/feats.scp ]; then
mkdir -p $data/.backup
echo "$0: moving $data/feats.scp to $data/.backup"
mv $data/feats.scp $data/.backup
fi
scp=$data/wav.scp # 得到音频路径列表
required="$scp $mfcc_config"
# $mfcc_config就是conf/mfcc.conf,所以required="$scp $mfcc_config"就相当于将“$data/wav.scp conf/mfcc.conf”赋给required
for f in $required; do # 检测wav.scp和mfcc_config.sh文件是否存在
if [ ! -f $f ]; then
echo "make_mfcc.sh: no such file $f"
exit 1;
fi
done
#这里其实就是判断是否有足够的文件,才继续往下运行
utils/validate_data_dir.sh --no-text --no-feats $data || exit 1;
# 使用validate_data_dir.sh 校验数据目录的脚本,这里会调用一些脚本来检测各种文件及目录是否存在等等
if [ -f $data/spk2warp ]; then
echo "$0 [info]: using VTLN warp factors from $data/spk2warp"
vtln_opts="--vtln-map=ark:$data/spk2warp --utt2spk=ark:$data/utt2spk"
elif [ -f $data/utt2warp ]; then
echo "$0 [info]: using VTLN warp factors from $data/utt2warp"
vtln_opts="--vtln-map=ark:$data/utt2warp"
fi
# 这块是是否通过VTLN(特征级声道长度标准化)(归一化),这里没有这两种文件,所以这里不调用
for n in $(seq $nj); do # 几个线程就分几个文件 .ark中存放音频mfcc特征
# the next command does nothing unless $mfccdir/storage/ exists, see
# utils/create_data_link.pl for more info.
utils/create_data_link.pl $mfccdir/raw_mfcc_$name.$n.ark
done
if $write_utt2num_frames; then
write_num_frames_opt="--write-num-frames=ark,t:$logdir/utt2num_frames.JOB"
else
write_num_frames_opt=
fi
if [ -f $data/segments ]; then # 如果存在segments文件则使用已有文件
echo "$0 [info]: segments file exists: using that."
split_segments=""
for n in $(seq $nj); do
split_segments="$split_segments $logdir/segments.$n"
done
utils/split_scp.pl $data/segments $split_segments || exit 1;
rm $logdir/.error 2>/dev/null
$cmd JOB=1:$nj $logdir/make_mfcc_${name}.JOB.log \
extract-segments scp,p:$scp $logdir/segments.JOB ark:- \| \
compute-mfcc-feats $vtln_opts --verbose=2 --config=$mfcc_config ark:- ark:- \| \
copy-feats --compress=$compress $write_num_frames_opt ark:- \
ark,scp:$mfccdir/raw_mfcc_$name.JOB.ark,$mfccdir/raw_mfcc_$name.JOB.scp \
|| exit 1;
else # 我使用的时候执行此分支
echo "$0: [info]: no segments file exists: assuming wav.scp indexed by utterance."
split_scps=""
for n in $(seq $nj); do
split_scps="$split_scps $logdir/wav_${name}.$n.scp"
# 后面是 exp/make_mfcc/train/wav_train.1.scp
done
utils/split_scp.pl $scp $split_scps || exit 1; # 使用脚本处理 scp=$data/wav.scp
# add ,p to the input rspecifier so that we can just skip over
# utterances that have bad wave data.
# 这里用run.pl提取特征开始
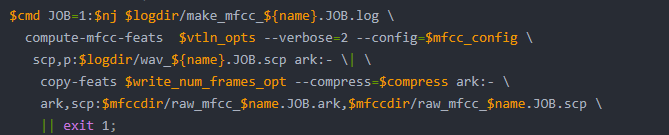
$cmd JOB=1:$nj $logdir/make_mfcc_${name}.JOB.log \
compute-mfcc-feats $vtln_opts --verbose=2 --config=$mfcc_config \
scp,p:$logdir/wav_${name}.JOB.scp ark:- \| \
copy-feats $write_num_frames_opt --compress=$compress ark:- \
ark,scp:$mfccdir/raw_mfcc_$name.JOB.ark,$mfccdir/raw_mfcc_$name.JOB.scp \
|| exit 1;
fi
#最后生成的应该就是mfcc/train 中的raw_mfcc_train.1.ark raw_mfcc_train.1.scp
if [ -f $logdir/.error.$name ]; then # 如果出现了错误则打印出log中最后的错误信息
echo "Error producing mfcc features for $name:"
tail $logdir/make_mfcc_${name}.1.log
exit 1;
fi
# concatenate the .scp files together.
for n in $(seq $nj); do
cat $mfccdir/raw_mfcc_$name.$n.scp || exit 1;
done > $data/feats.scp || exit 1 # 将所有的scp文件拼接起来输出到data/mfcc/train/feats.scp
if $write_utt2num_frames; then
for n in $(seq $nj); do
cat $logdir/utt2num_frames.$n || exit 1;
done > $data/utt2num_frames || exit 1
rm $logdir/utt2num_frames.*
fi
# 删除过程文件
rm $logdir/wav_${name}.*.scp $logdir/segments.* 2>/dev/null
nf=`cat $data/feats.scp | wc -l` # 输出文件的行数
nu=`cat $data/utt2spk | wc -l`
if [ $nf -ne $nu ]; then # 检测特征的数目与音频文件的数目是否相同
echo "It seems not all of the feature files were successfully processed ($nf != $nu);"
echo "consider using utils/fix_data_dir.sh $data"
fi
if [ $nf -lt $[$nu - ($nu/20)] ]; then
echo "Less than 95% the features were successfully generated. Probably a serious error."
exit 1;
fi
echo "Succeeded creating MFCC features for $name"
这里可以发现,整篇文档读完后并没有涉及到之前理论分析的操作,其实对应的理论操作在这里:
底层语言使用C++写的,与理论相对应,但这里不推荐先学习底层。