Awk是一种便于使用且表达能力强的程序设计语言,可应用于各种计算和数据处理任务。初识实在kaldi的清华数据集里面,在准备数据阶段使用到Awk来对文件名文字进行拆分和,老师提到那是十分强大的文本处理工具,机缘巧合在和斌哥在所里聊天时斌哥也提到了,正巧这次有了个关于Awk的任务给我,斌哥写的差不多了,我们先来看看吧。
提取function=1 的数据块
egrep -A 27 "^[[:space:]]{8}id:[[:space:]]{1}function=1[[:space:]]{1}process" waiting.txt > 1E
这里的 egrep 乍一看感觉很陌生,其实和 grep -e 类似,支持元字符的匹配,而这里的 -A 在手册中是这么写的:

对正则表达式的解读如下:
^: 表示字符串开始。
[[:space :]] : 表示匹配空格。
{8}: 表示匹配8次,即8个空格
id:[[:space:]]{1}function=1[[:space:]]{1}process:
因为内容多有重复,这里就一起解释为:id:(一个空格)function=1(一个空格)process.
放在这里的意思是 在 waiting.txt 中,匹配 “(八个空格)id:(一个空格)function=1(一个空格)process“这样的字符然后输出27行到 1E 文件中。这里开着如此多的数据为什么是27行就可以了呢?原因是这些数据之前其实是空格隔开,但没有实际换行,所以其实 27 行可以包含整个带处理数据块。
这里斌哥给了我一个任务,我一开始还想复杂了,只是需要做一个预处理删除function3,这个过程在命令行完成对我来说有些吃力,学习后我写得如下脚本:
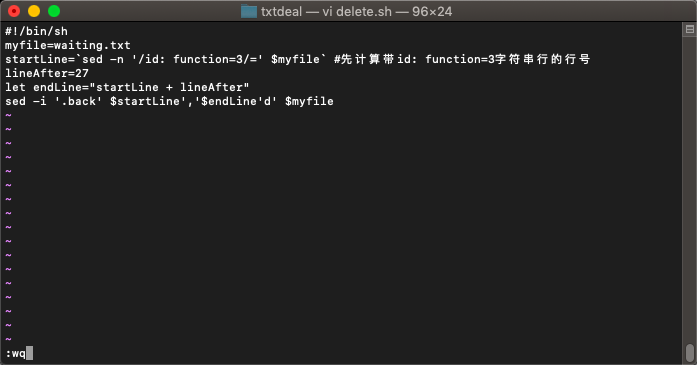
这里会有一些bug,但是逻辑上是行得通的,斌哥的方法和我倒是不一样,斌哥取1,2分别提取,然后连接
#!/bin/bash
file1=test11.txt
cat $file1| egrep -A 27 "^[[:space:]]{8}id:[[:space:]]{1}function=2[[:space:]]{1}process" > temporary.txt
cat $file1| egrep -A 27 "^[[:space:]]{8}id:[[:space:]]{1}function=1[[:space:]]{1}process" |
awk '{print}END{system("cat temporary.txt")}'
|egrep "(^[[:space:]]{8}id:[[:space:]]{1}function=[0-9])|(scan start time)|(^[[:space:]]{10}binary:)"
|sed -e 's/ id: function=[0-9] process=0 scan=\([0-9]*\)/Scan \1/' -e 's/ cvParam: scan start time, \([0-9]*\.[0-9]*\), minute/Retention time \1/'
|awk '/binary/{for(i=1;i<=NF;i++)a[i]=a[i]?a[i]"\t"$i:$i;if(++q==2){for(i=1;i<=NF;i++){print a[i];delete a[i];q=0}}next}1'
|awk '/binary|\[/{$0=" "}1'
|awk 'BEGIN{i=1}{if($0~/^Scan[ ]*1$/){$0="";printf "FUNCTION\t%d\nScan\t1",i;++i}}1' > finish.txt
rm temporary.txt
不得不说斌哥用正则表达式用的是真溜啊….